

版本:v2.12

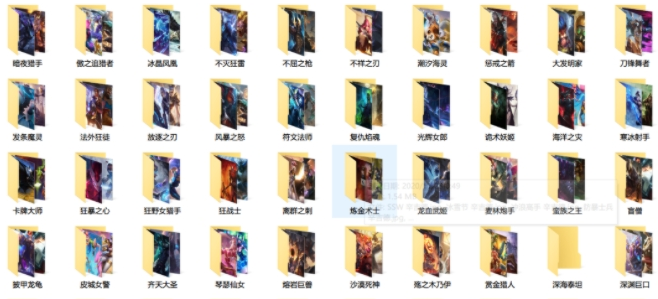
python爬取lol官网英雄图片代码可以帮助用户对英雄联盟官网平台的皮肤图片进行抓取,有很多喜欢lol的玩家们想要官方的英雄图片当作自己的背景或者头像,可以使用这款软件为你爬取图片资源,操作很简单,设置一些保存路径就可以将图片保存到这个文件夹里了。
因为最近在学习python,这个代码也是百度了很长时间来写的。
确实不会英语。。对英语一点也不敏感!
虽然某易论坛已经有python的中文模块了,但是不想去用中文,也算是挑战一下自己把!
自己对易语言比较熟悉,所以有点经验来写python,从另一个角度来说的话,python也算比较好理解!
下面的代码注释写的很详细!可以一起学习!算是给自己的第一课吧!
下面截图没有爬完的效果图(图片大小为980*500或者1024*630的图片);所以这个清晰度还不叫壁纸吧!

import requests,os,json,time
#requests为网页操作模块;用来取出英雄列表和皮肤列表
#os为系统模块,用来写文件和创建目录
#json为json解析模块,用来解析返回的数据
#time为时间模块,用来延时
js = requests.get('https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js')#先访问这个网址,获取英雄列表
herolist = js.json()#取出返回的json格式
for i in herolist['hero']:#循环英雄列表
name = i['name']#取出英雄的名字
if os.path.exists('LOL壁纸'):#判断根目录是否存在
print('创建目录失败,目录已存在;')
else:#不存在就创建这个目录
os.mkdir('LOL壁纸')
print('创建目录:LOL壁纸;')
if os.path.exists('LOL壁纸⁄⁄' + i['name']):#判断根目录LOL壁纸下子目录为英雄名的目录是否存在
print('创建目录失败,目录已存在;')
else:#如果不存在就创建这个目录
os.mkdir('LOL壁纸⁄⁄' + i['name'])
print('创建目录')
heroID = i['couponPrice']#赋值英雄id
english_name = i['alias']#赋值英雄的英文名
photos_back = requests.get(f'http://lol.qq.com/biz/hero/{english_name}.js')#读取以英雄英文名.js的网址来获取皮肤列表
photos_back_text = photos_back.text#取出来返回的字符串
photos_back_text = photos_back_text.replace('if(!LOLherojs)var LOLherojs={champion:{}};LOLherojs.champion.'+english_name+'=','')
photos_back_text = photos_back_text.replace(';', '')
photos_back_text = json.loads(photos_back_text)#以上两行行处理一下返回的字符串用来转换为json的格式
for n in photos_back_text['data']['skins']:#循环一下皮肤列表
photos_back_byte = requests.get(f'https://game.gtimg.cn/images/lol/act/img/skin/big{n["id"]}.jpg')#读取一下以皮肤ID为网址的图片地址
if n['name'] == 'default':#判断一下是不是默认皮肤
skin_name = str(name)#如果是默认皮肤,就以英雄名字来命名
else:#如果不是就以皮肤名字命名
skin_name = str(n['name'])
print(f'英雄名:{name};英雄ID:{heroID};皮肤ID:{n["id"]};英雄英文名:{english_name};皮肤名字:{skin_name};')#将状态打印出来
if skin_name.find('/') != -1:#后面运行的时候发现一个问题,如果皮肤名字有一个'/'字符串的话直接就会报错,所以这里来寻找一下皮肤名字有没有'/'这个字符串
skin_name = skin_name.replace('/','')#如果存在这个字符串就把他替换掉
wb = open('LOL壁纸⁄⁄' + name+'⁄⁄'+ skin_name +'.jpg','wb')#打开这个图片文件
wb.write(photos_back_byte.content)#把读取出来的图片网址以字节集的形式保存文件
wb.close()#关闭这个文件
print(f'保存{name}的{skin_name}成功!')#打印保存成功
print('延迟3秒继续')
time.sleep(3)#延迟3秒,运行的时候发现如果速度过快,网站就会返回错误信息
以上就是python爬取lol官网英雄图片代码的全部内容了,快快收藏非凡软件站下载更多软件和游戏吧!
 飞米软解压视频播放控件
飞米软解压视频播放控件

 英雄联盟助手
英雄联盟助手 酒精测试软件大全
酒精测试软件大全